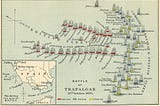
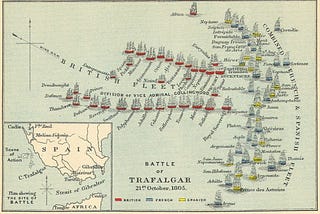
PinnedAngelina YangHow to Find a “Good Boss” and the Battle of TrafalgarWhen I first graduated and was looking for a job, I never thought about what I want from a manager. I probably selected the highest paid…Mar 6, 2023Mar 6, 2023
Angelina YangNew Vision-Language Solution for Extracting Tables and Figures from PDFsAs researchers and technical writers, we often find ourselves sifting through countless research papers, trying to extract the most…2d ago2d ago
Angelina YangUnifying Context Ranking and Retrieval-Augmented Generation with RankRAGLarge language models (LLMs) have become increasingly powerful tools for tackling a wide range of knowledge-intensive natural language…Jul 18Jul 18
Angelina YangSilicon Valley AI Events This Week+ Discount Code for AI Event with Fei-Fei Li and Eric Yuan🤩Lots of events for friends in the Bay Area: But before we go there:Jul 8Jul 8
Angelina YangOld Wine in a New Bottle: How HippoRAG Revolutionizes Retrieval with Knowledge GraphsIn the ever-evolving world of AI and language models, it’s easy to get caught up in chasing the latest and greatest innovations. However…Jul 62Jul 62
Angelina YangUnlocking the Power of Large Language Models with GraphRAGIn today’s data-driven world, the ability to extract meaningful insights from vast troves of unstructured information has become…Jul 34Jul 34
Angelina YangNew AI Benchmark to Measure RAG Model PerformanceAs generative AI continues to captivate the tech world, one emerging approach that’s generating a lot of excitement is retrieval-augmented…Jul 2Jul 2
Angelina YangCreating a Winning Value Proposition: The Key to Building a Product People Will Actually BuyIf you are building or selling a product, it’s crucial to have a compelling story that highlights why customers should invest in it.Jul 22Jul 22
Angelina YangBuilding Knowledge Graphs: Traditional NER vs. LLMsKnowledge graphs have become increasingly important for structuring information and enabling advanced querying and reasoning capabilities…Jul 11Jul 11